一、巴甫洛夫和他的狗——如何让狗听到铃声就流口水?(经典条件反射)
早在上中学的时候,我们就学过巴甫洛夫的条件反射实验,但实际上巴甫洛夫是研究消化系统的。过去人们在研究消化系统都是给动物切腹,这就非常不人道。所以巴甫洛夫采用了研究狗的唾液的方法,起初他在狗的嘴边连了一根导管,根据唾液的分泌量来研究。
之后的故事就和书上讲的一样了,随着实验的推进,狗会在见到食物或者闻到食物就开始分泌唾液,到了后期,狗听到助手开门的声音,甚至更早,在听到助手的脚步声在走廊里响起的时候,就开始分泌唾液了。
有一些科学家认为这个研究的方向偏离了原本的目标,觉得特别愚蠢,但是巴甫洛夫认为研究这种灵魂分泌液的行为比研究唾液的化学成分要更有意思,所以他就改变了研究的焦点,到了今天,可以说这个改变让心理学的进程产生了技术爆炸。
那么他后来的实验是怎么做的呢?
在实验的开始阶段,首先在整个过程中加入一个跟唾液分泌完全没有关系的刺激,铃声。 我们知道,生活中狗听到铃声只会让他竖起耳朵听是哪儿来的,并不会分泌唾液。可是如果在铃声响起之后再提供食物,小狗本身会对食物产生非条件反射,也就是分泌唾液,当这种匹配反复进行多次之后,狗在寻找音源定位的反应就减弱了,狗会把铃声与食物关联起来。
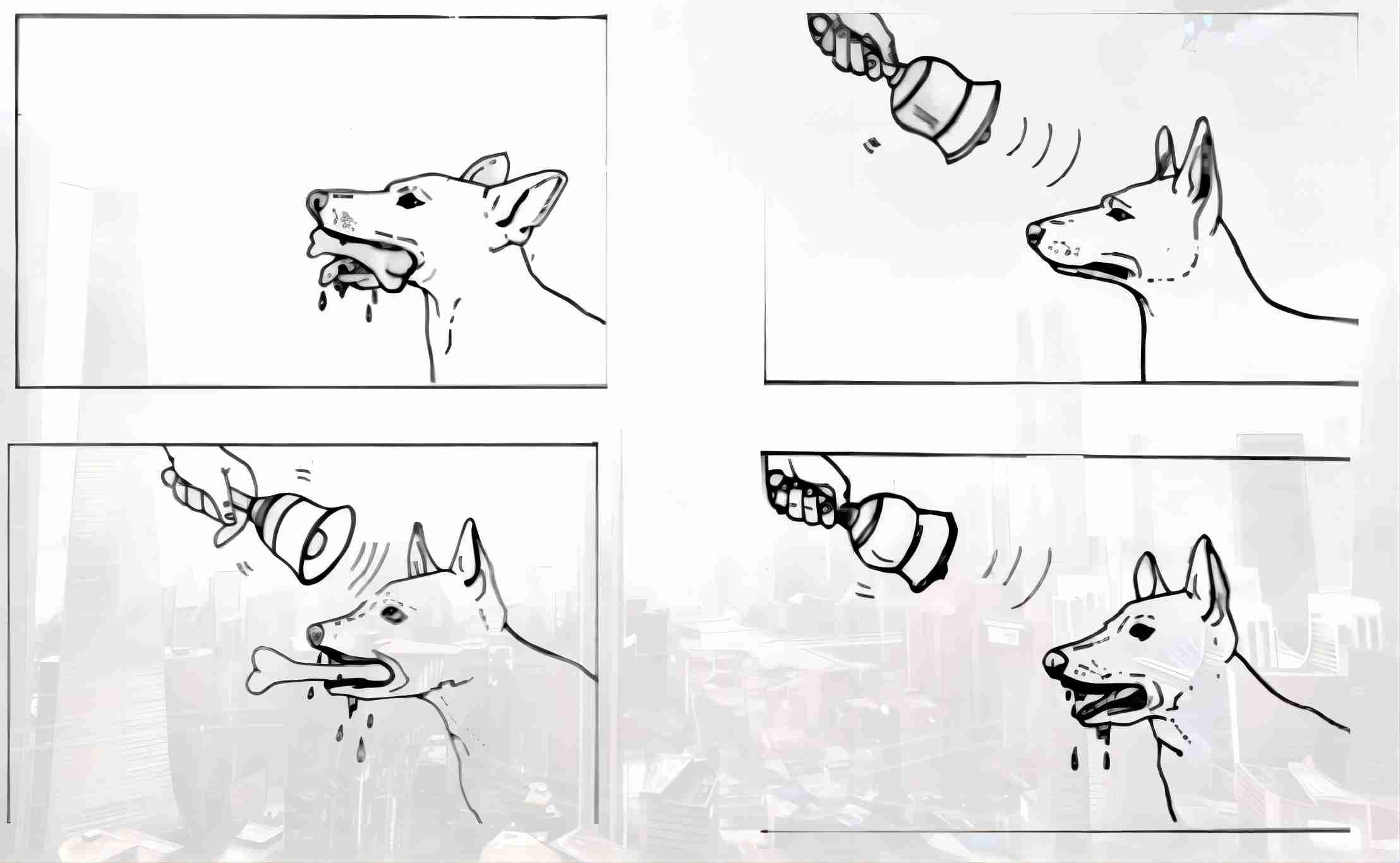

也就是说,即使不提供食物只是呈现铃声,小狗也会如期的分泌唾液,巴甫洛夫随后又用了其他的中性刺激来实验,比如说灯光、节拍器等等,用这些来重复验证这种现象的普遍性。
二、桑代克的猫——猫是如何学会密室逃脱的?(试误学习)
说完巴甫洛夫的狗,就不得不说桑代克的猫,他的实验和巴甫洛夫实验是同时期的。桑代克的这个实验你可以称之为“密室逃脱”,当然这和人类的密室逃脱还不一样,人具有归纳、推理等较强的逻辑思维能力,而动物就不一样。 所谓的“密室”实际上就是一个有机关的笼子。
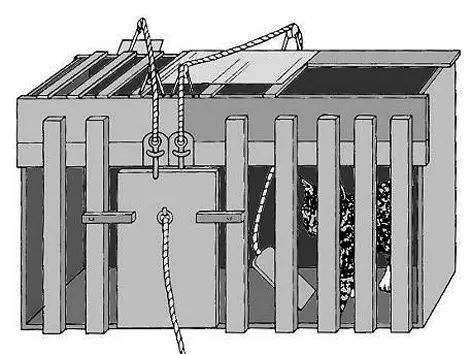
最开始,小猫只是在笼子里面胡乱的抓和拍打笼子的各个部分,几分钟之后他就获得了成功的反应,比如说拉动了绳子或者扳动了某个按钮,最终猫打开了笼子顺利逃脱,并且获得了在门口放着的食物。
当小猫重新被放回笼子之后,它逃离这个笼子所耗费的时间就会减少一些,而经过几次尝试之后,他就能够学会不再去乱碰乱咬,而是直接进行正确的行动,所有其他没有用的行为会逐渐的消失。这些成功打开笼子的特定行为,因为愉快的结果而得到了保留,至此小猫就学会了如何打开笼子。
这是一系列刺激所引发的连锁反应,所以对于小猫来说呢,刺激的情境就是这个密室逃脱的笼子,目的呢,就是从这个笼子当中逃出去,并且获得食物那么连接,这两者之间的适当的反应就是拉绳子这种能够打开笼子的行为。
根据实验,可以画出猫的学习曲线。桑代克把猫在迷笼中不断地尝试、不断地排除错误最终学会开门出来取食的过程称为尝试错误学习,并提出了学习的“试误-学习”理论。
三、斯金纳的老鼠——如何让老鼠学会按压杆?(行为塑造)
阿猫阿狗讲完了,就得讲老鼠了。斯金纳是研究行为心理学的一位心理学大师了,他受到了桑代克的启发,扩展了巴甫洛夫和桑代克的研究。
他的研究被称为操作性条件反射,通俗点说就是说我们可以操纵老鼠或者鸽子行为所引发的那个结果,而不是由特定的那个刺激所直接引发的。也就是说,操作性条件反射的行为是自发的,而经典条件反射的行为是非自愿的。
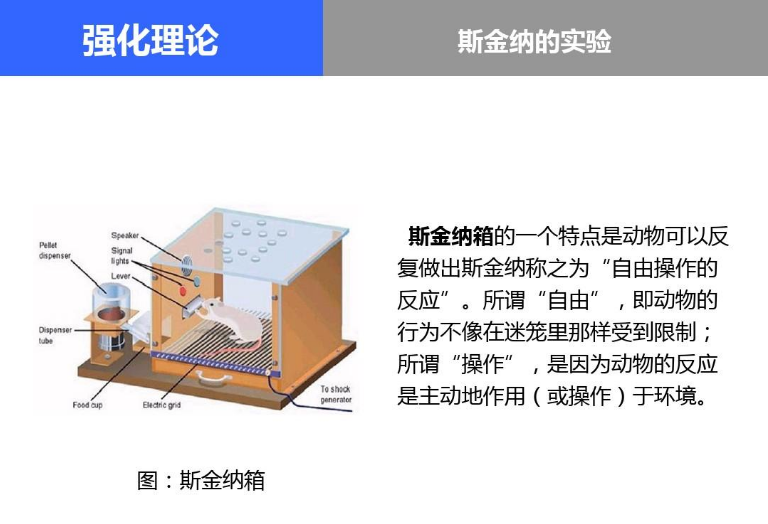
斯金纳发明了一个装置,这就是我们现在老说的“斯金纳箱”。
这个箱子里有个压杆,当老鼠按动按钮的时候就给他投食。那么这就有一个问题,我们知道在自然界中,老鼠为了生存会需要用爪子去学会各种技巧,比如打洞,但是按压这个压杆并不是他们必备的生存技巧,那么我们如何塑造老鼠按压杆的这个行为呢?
这里采用了一种连续接近塑造法,简单来说,就是要把跟这个目标行为相似或相近的门槛相对较低的行为强化强化再强化,然后逐渐将行为的门槛提高,直到把压杆的这个行为塑造出来。
比如,在斯金纳箱的这个实验中,
首先,让老鼠饿一天,这个过程叫食物剥夺,就是为了让食物成为一种非常有力的强化物,这样老鼠就不会受到其他的干扰;
然后,有计划地让食物出现在食物漏斗中,让老鼠知道去哪儿能够找到食物;
最后,就是附加条件,比如让老鼠往杠杆方向移动一点食物就会出现,逐渐提升条件的难度,比如老鼠碰到杠杆才会提供食物,这个难度提升直到老鼠按压杠杆为止。
通过这种渐进式的引导,最终老鼠就会学会按压杠杆。那么你可以发现,游戏中的签到领礼包就是一个“斯金纳箱”。
在后续的实验中,斯金纳还发现了,无论实验对象是老鼠还是鸽子,都会导致三种后果的发生:
中性后果,就是对后续的行为没有什么影响;
行为强化,也就是强化某种行为,让他更容易更可能发生;
惩罚减弱,让某种行为不太可能继续发生。
四、行为强化——正强化和负强化
在实验当中,为了增加某种行为出现的概率呢,研究者会使用强化物。也就是跟行为相伴的某一种刺激,那强化物所造成的强化又分为两种情况。
首先是正强化,也就是给实验对象一个良性的或者说是比较好的刺激,这个在现实生活中很常见,比如说我们考试考了100分,那可能会得到一个礼物;
再比如加班加得很辛苦吗,会得到一些奖金。 在这些被鼓励的行为发生之后,越早给出强化物,那么这个强化物所能够带来的这个效果也就越大。
奖励的方式可能是一级强化物,比如说满足生理需要的食物等等,或者是刺激强化物,比如说钱、表扬、赞赏等等。
这在游戏里我们习以为常的一些奖励其实都是正强化,比如完成任务的时候得到的游戏币或者装备的奖励,这个就是最直接的正强化。
这些强化物,让我们在付出了辛苦之后得到了相应的满足,鼓励我们继续去玩游戏。除此之外正强化还会在游戏中被设计成成就系统,这个成就系统是一个非常有意思的东西,因为除了成就本身之外,游戏并没有提供什么实质性的奖励,但是这种正强化,会让玩家就由于刺激的驱动,去尝试游戏设计师希望玩家去尝试的行为。
另外一种就是负强化,跟正强化刚好相反,也就是去掉一个负面的或者说是不好的刺激。这种负面的刺激,也是为了引发出所希望的行为而设计的。 那在斯纳金的另外一个实验当中,老鼠按压杆是可以避免遭受到电击的,也就是说老鼠可能10秒钟会被电一次啊,但是一旦它按了压杆,这10秒就不被电了,再过10秒你没有压感又要被电一下。
五、行为减弱——正惩罚和负惩罚
我们可能都很熟悉惩罚这件事,在强化某种行为的时候,有强化物,对应的,惩罚的时候呢,也会有惩罚物,它是任何一种能够降低行为出现概率的刺激。
这个刺激同样分为两种,也就是正惩罚和负惩罚。正惩罚,是指要施加一个负面的、不好的刺激。 也就是当不当行为出现的时候呢,给予处罚,给对方一种让他感到不快的刺激。
法制就是正惩罚一个例子,违法就给予相应的处罚,简单粗暴,但是非常有效。
那么在惩罚的时候必须要注意四点:惩罚的是什么、意义要明确、时间要适当、强度比较合适。否则会起不到引导和强化行为的作用。
回到负惩罚,就是说去掉一个良性的或者说是好的刺激。 这种负惩罚比正惩罚更为常用啊,因为它很温和,所谓去掉一个良性的刺激,就是指当这种不适当的行为出现的时候呢,原本你可能能够得到的奖励就不再给你了。
比如说有一个故事:
有一群孩子在一位老人家门前嬉闹,叫声连天。
几天过去,老人难以忍受。于是,他出来给了每个孩子10美分,对他们说:“你们让这儿变得很热闹,我觉得自己年轻了不少,这点钱表示谢意。”
孩子们很高兴,第二天仍然来了,一如既往地嬉闹。老人再出来,给了每个孩子5美分。
5美分也还可以吧,孩子仍然兴高采烈地走了。
第三天,老人只给了每个孩子2美分,孩子们勃然大怒,“一天才2美分,知不知道我们多辛苦!”他们向老人发誓,他们再也不会为他玩了!德西效应
六、4种强化行为的套路——部分强化的魔力
这个套路还是源于斯金纳的实验,在一次实验当中,当时他没有足够的食物来奖励那些埋头苦干的老鼠,为了节省食物,它仅仅在经过一段时间的间隔之后才会给老鼠食物,无论这期间老鼠按压了多少次杠杆,都不会得到更多的奖励。 最后的结果是什么呢?
这些只经过部分强化的老鼠,在行为强化的程度上丝毫不逊色于连续强化的老鼠。
更重要的是,当按压杠杆之后再也不给食物,也就是消退训练开始,这些经过部分强化训练的老鼠,会比经过这种连续强化训练的老鼠能坚持更长的时间,才会产生行为的消退,在这之前,他们比以前更加不知疲倦地去反复的按压压杆。
这就延伸出了对4种不同的强化计划的研究:
在强化物的维度,可以按照比率计划,也就是次数;
在时间的维度,可以按照间隔计划,也就时间作为参照。
而在每种情况之下,又有不变的固定的强化模式和有不规则的可变的强化模式两种。
这4种不同的强化套路哪个更有效呢?那么一起来看看。
6.1 固定比率强化
在固定比率计划当中,强化物在实验对象做出一定数目的行为之后才出现。
由于行为跟强化是直接相关的,固定比率计划产生的行为速率非常高,因为只要你行为够频繁,比如老鼠按压杠杆的速度够快,那么老鼠就可以通过积累按压的数量来得到跟劳动完全相符的食物,或者叫做强化物的反馈。
固定比率计划在每次强化之后,都会产生一个停顿,在面对没有事先训练动物做出大量行为的时候,所要求的行为次数过度延缓行为速率就会导致这种行为的消退。
比如说,游戏中一旦玩家决定继续向前不断的去重复这个行为去努力获得奖励,那么他们就会马上毫不犹豫的尽快的重复这个行为,并且不断的去加速,以最快的效率来完成一定数量的这种行为来获得奖励,固定比率计划之下有明显的停顿,因为在这段时间之内玩家几乎失去了玩游戏的动力,这个可能会导致玩家离开游戏。
6.2 可变比率强化
在固定比率强化种,两次获得强化物之间需要完成的行为的次数是确定的,不管它是多还是少,重点是我们能够明确的知道,到底我还要做多少次这样的行为才能获得奖励。而可变比率强化,能确定的只是强化物之间的行为平均值,换一句话说就是只知道出现的概率。

这个就比如说老虎机,在这个计划之下,会用非常高的频率和稳定的流程来作出相应的行为,尽管这个频率没有像固定比率计划那么高,但是也不像固定比率计划存在停顿的问题,所以虽然说可能性很小,但是理论上总有可能在第1次行动之后就获得奖励。这种赌博感,总会让人有要去尝试的理由。
6.3 固定间隔强化
固定间隔强化的意思是说,强化物是在经过一个固定的时间间隔之后,实验对象第一次做出行为才会出现的。
这个和你在这个时间间隔种发生多少次的行为没有关系。在固定间隔强化的过程中,动物的行为速率呈现一个扇形的模式,每次强化结束后,动物就不再做出任何反应,但是随着奖励时间的接近,动物去尝试的行为次数就会越来越多。
现实生活中,我们经常说deadline是第一生产力,放暑假我们很多人肯定在返校前几天才开始突击作业,这不仅仅是拖延症,同时也是因为强化物。
这几年上线的游戏中有一种机制,就是固定间隔计划的例子,比如每隔30分钟就会出现一个礼包或者福袋。
6.4 可变间隔强化
在可变间隔计划当中,平均的时间间隔是预先确定的,比如平均经过20秒就可能会呈现一次强化物。
这种强化会产生中等,但是却比较稳定的行为速率,而且在可变间隔计划当中的消退是渐进的,比固定间隔强化的消退要慢很多。
在实验中,经过可变间隔强化后的鸽子,在强化中止之后仍然会去啄食的,实验记录,它在最初的4个小时里着实了18000次,经历了惊人的168个小时行为才完全消退。
比如,上学的时候,有一些老师喜欢不定期的突击测验,这个时候我们大都会在上这个老师的课前临时抱抱佛脚,复习一下。
所以,可变间隔强化和可变比率强化类似,会给我们一个理由,让我们感觉这个强化物可能马上就要来了,同样也能够产生稳定和持续性的行为。
以抽奖为例,(A)可变间隔强化是平均1个小时抽一个大奖;(B)可变比率强化是有10%的概率能抽到大奖。
(A)强化下,只有在间隔1个小时左右才会高频产生行为,等抽到奖了就不再继续,注意力会转移。
(B)强化下,可能会不断地去抽奖。
所以说,可变间隔强化后,实验对象的注意力是可能会转移的,在行为的连续性上没有可变比率强化高。
内容整理来源:陈京炜教授,《游戏心理学》,中国传媒大学,中国大学MOOC
https://www.icourse163.org/course/CUC-1003769001?tid=1003987006
本文作者:𝙕𝙆𝘾𝙊𝙄
文章名称:我们的行为到底是如何被引导和强化的?
文章链接:https://www.zkcoi.com/365up/psychology/203.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 