现在不用这么麻烦了,可以使用UNIQUE函数
原始数据如图所示,一共12列,每列数据几十到几百行不等
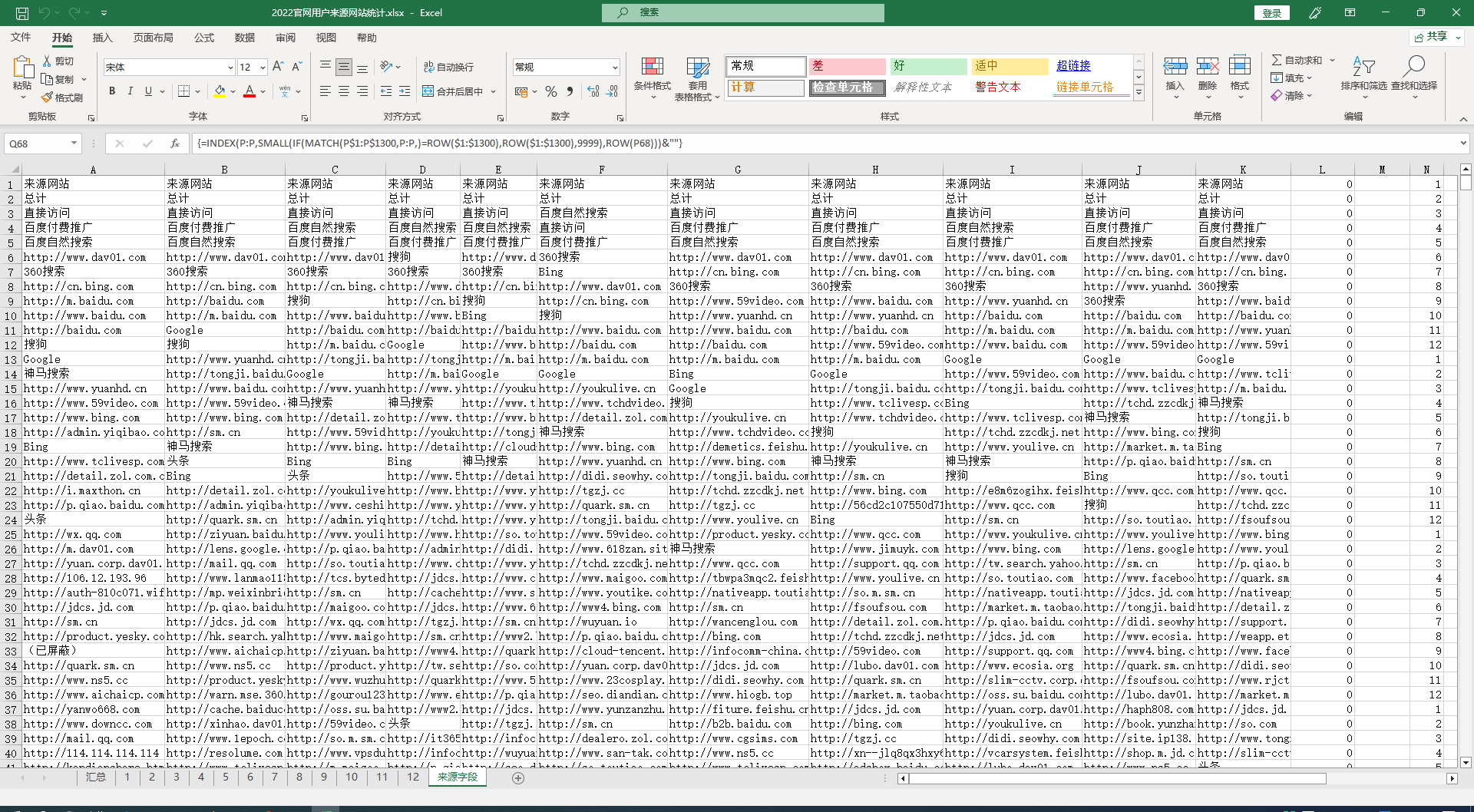

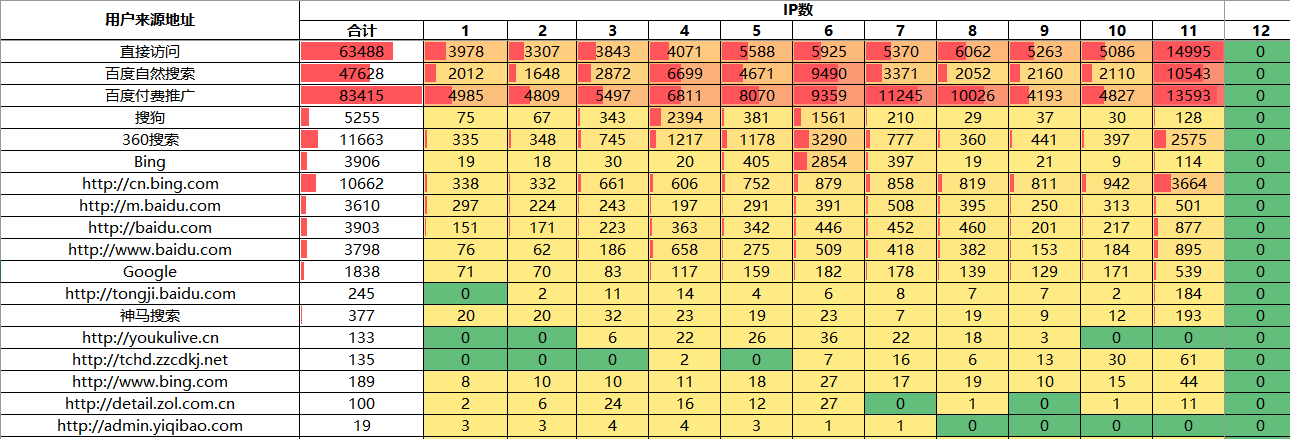
需求:提取非重复项,合并成一列。
思路还是比较简单,我们首先将所有值整理到同一列,然后剔除重复项,但是由于考虑到后续的更新和复用,不能直接用excel剔除重复项的功能,需要用公式实现。
步骤①:将所有值整理到同一列
通过坐标定位将所有值合并成一列,因为有12列,那么横纵坐标分别可以用MOD()和INT()两个行数实现,如第一行第一列的横坐标为=INT(ROW(A12)/12)、纵坐标为=MOD(ROW(A12),12)+1,有了坐标然后使用INDEX()获取坐标值即可,这里为了避免错误加了个IFERROR。
=IFERROR(INDEX($A$1:$M$100,INT(ROW(A12)/12),MOD(ROW(A12),12)+1),"")
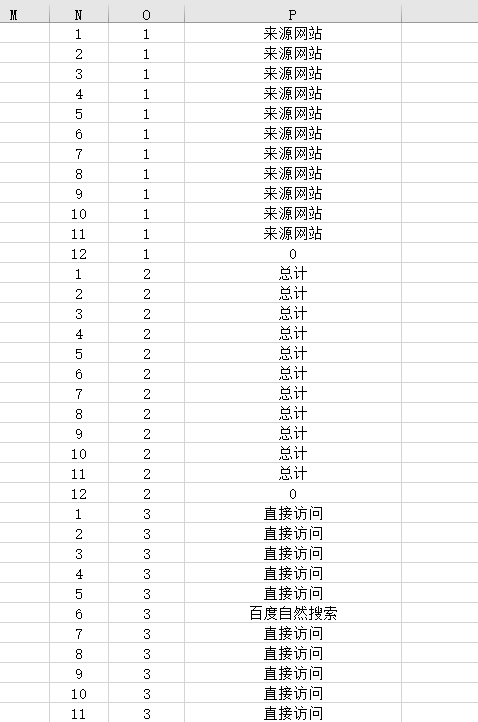
该数据形式如图所示,N为纵坐标,O为行坐标,P为值,也可以手写,但为了确保可复用,公式复制到第一行,直接下拉填充即可。
步骤②:获取重复项的第一个值的位置
获取了所有值的列之后,通过MATCH()获取重复值的位置,这里的思路是,相同的值MATCH()的位置为第一次出现的位置,我们可以通过IF()函数增加一个判断,当MATCH()的位置和当前的位置是相同的,那么这个位置就是我们需要的,否则就不是我们需要的。
=IF(MATCH(P$1:P$1300,P:P,)=ROW($1:$1300),ROW($1:$1300),9999)
Q为=MATCH(P$1:P$1300,P:P,),R为=ROW($1:$1300),S为上述公式,最终实现的是只获取值第一次出现的位置,其他的都是9999,当然如果重复次数超过9999可以替换。
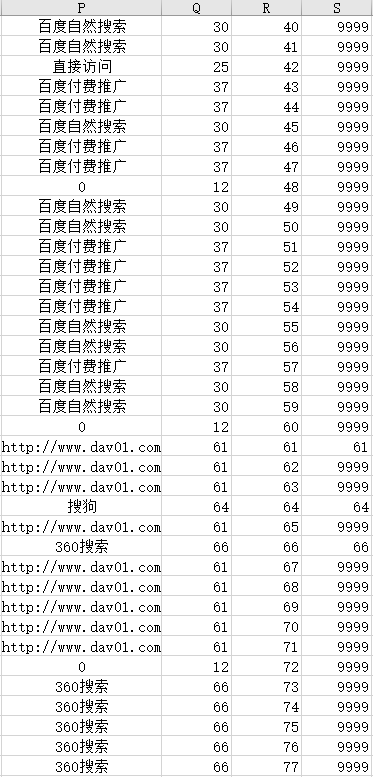
步骤③:获取值出现第一次位置的坐标
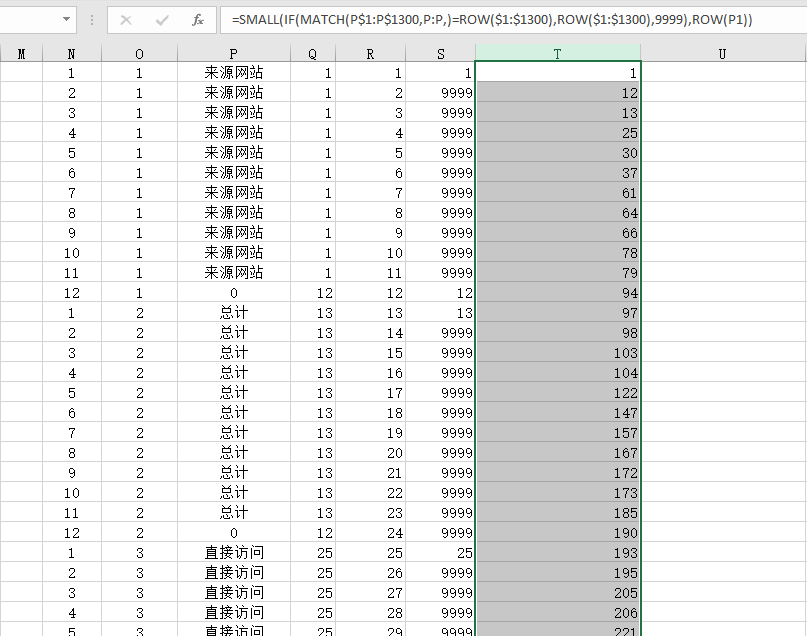
这里需要使用SMALL()函数,剔除步骤2中为9999的值,此时获取该值在P列中的位置。
=SMALL(IF(MATCH(P$1:P$1300,P:P,)=ROW($1:$1300),ROW($1:$1300),9999),ROW(P1))
可以看到使用SMALL()函数后,直接剔除了9999,并且下拉填充时自动依次填充取值。
步骤④:对P列使用INDEX(),自动剔除重复项
这里增加了一个&"",避免出现0。
=INDEX(P:P,SMALL(IF(MATCH(P$1:P$1300,P:P,)=ROW($1:$1300),ROW($1:$1300),9999),ROW(P1)))&""
最终完美自动剔除重复项,并且生成了一列。
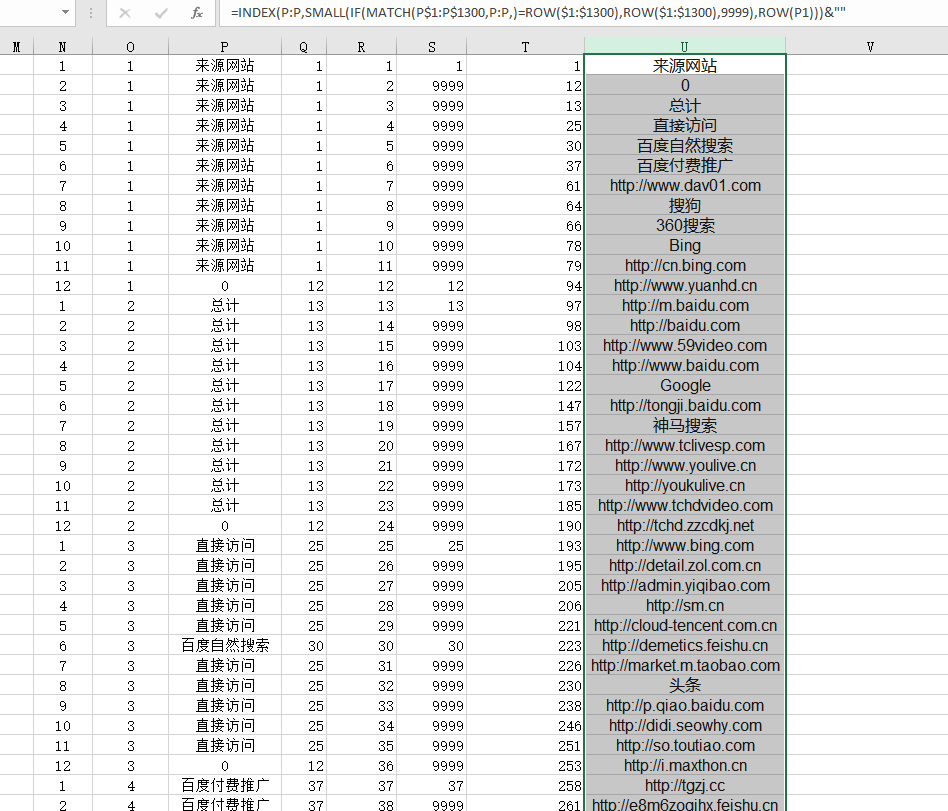
在此基础之上,可以丰富一些模板格式并且发给其他人复用了。
本文作者:𝙕𝙆𝘾𝙊𝙄
文章名称:EXCEL中如何用公式实现剔除重复项(获取不同列中的非重复值,并且单独生成一列)
文章链接:https://www.zkcoi.com/idea/skills/2419.html
本站资源仅供个人学习交流,请于下载后24小时内删除,不允许用于商业用途,否则法律问题自行承担。
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 